Reimagining Development Processes
EG Public Alpha Announcement
We're excited, today is the day. We've been working on this for a bit and we've finally arrived! Our public alpha release blog post!
It's going to be a long one folks, there is a fair bit of material to cover. But hopefully it'll be interesting; We started this journey because we are tired of the lackluster and stagnant state of the ci/cd ecosystem, and more recently the state of MLOps.
At the end we'll cover some how we've been using EG along with some early customers, and where we are going from here.
The Wish List
Ever since I was first introduced to jenkins back in 2011, I've loved the value that CI/CD systems have provided the teams I've been on. But its also been a very sad affair because they tend to be under utilized, a pain to maintain, and provide poor developer experiences.
Lets cover the bullet list of the issues as we see them in traditional CI/CD systems, and then we'll go through most of them and how EG addresses each. We'll cover using them in machine learning operations (MLOps) in a separate article at a later date.
- poor version control for plugins and silo'd ecosystems.
- slow iteration cycles when making improvements.
- no IDE support
- YAMLscript. Bash. etc.
- low server utilization.
- poor introspection tooling for debugging.
- insecure shared compute.
- limited/no code reuse between workstations, CI/CD, and deployed environments.
- poor support for execution graphs.
- infrastructurally complex.
- often no builtin static analysis tooling.
- often no builtin distribution channels both private and public (rpm/deb/flatpak/container repositories)
- the ability to be controlled via APIs for integrating workloads directly into production environments.
By resolving the above we hope to consolidate the following infrastructure into a single operationally simpler platform that helps developers from authoring code all the way to online systems in production:
- Codespaces
- CI/CD runners
- Orchestration systems (airflow)
- Package repositories.
Is this ambitious? absolutely. is it doable? we think so, especially with the virtualization we have available today, specifically WASI.
Solving Silo'd ecosystems and poor version control
Basically every CI/CD system has plugin systems but its tailored to that platform.
Jenkin's has its plugins. Github has its actions. etc. Each with its own way of doing things and its own set of tooling. Each with their own caveats and limitations, obligatory xkcd. Of the two mentioned jenkins took the better approach and at least used java's existing ecosystem to bootstrap from.
EG has taken a similar approach to jenkins but we're leveraging golang's ecosystem, and avoiding plugin api's by not trying to make a singular UI. This gives us a few advantages:
- we get world class dependenency management out of the box using golang's builtin tooling.
- releasing a library for use is as simple as creating a git repository.
- builtin vulnerability detection and reporting.
- wide range of architectures supported.
- fast build times.
- fast dependency resolution times.
- highly cachable builds.
- almost any OS agnostic golang module can be used in your EG workloads.
- easy distribution
Let's demonstrate updating EG in one of our workloads:
go -C .eg get github.com/egdaemon/eg@latest && go -C .eg mod tidy
Because we have an ABI layer via our wasi runtime we can ensure long term compatibility where necessary. But since we're using golang we actually have tooling that can automatically update your workloads when we do need to introduce backwards incompatible changes. (we dont anticipate this happening very often)
Effectively we've made it as simple as we could to share code for our workloads and to ensure we can move the ecosystem forward.
Solving slow iteration cycles
Buffer bloat
Usually the process of updating a ci/cd pipeline requires an incredibly slow iteration cycle of:
- identify problem.
- make changes.
- wait for compute to become available.
- wait for compute to run the workload.
- review results of run.
- repeat.
EG can run your workloads locally on your workstation. its as simple as eg compute local {workload}.
This has a few advantages:
- no additional load on your CI/CD compute.
- no waiting in a queue.
- full power of your workstation and personal credentials available to you.
- ability to isolate and run just the task you want to run.
Caching
Another giant contributer to the interation cycle are cold starts. Often CI/CD pipelines are not properly setup so you need manually configure any caching you want to do. EG design allows us to seamlessly configure your pipelines to cache essentially automatically. observe a component of our backend's pipeline that runs golang's test.
func Tests(ctx context.Context, _ eg.Op) error {
// Here we setup a shell runtime for golang.
// this properly sets the shell environment for any
// commands it builds to properly place artifacts in
// the caching directory. We have these runtimes for
// many languages and frameworks and they're trivial
// setup.
daemons := eggolang.Runtime().Directory("daemons")
return shell.Run(
ctx,
// Run the test suite, eg's golang module actually has
// tasks that can automatically locate and execute compilations,
// and tests for multiple modules within a single repository.
// we're just doing it manually here as a reference.
daemons.New("go test ./..."),
)
}
Here is what it takes to integrate a new build tool into eg similar to what we just showed for golang.
// Package egyarn has supporting functions for configuring the environment for running yarn berry for caching.
package egyarn
import (
"os"
"path/filepath"
"github.com/egdaemon/eg/internal/envx"
"github.com/egdaemon/eg/internal/errorsx"
"github.com/egdaemon/eg/runtime/wasi/egenv"
"github.com/egdaemon/eg/runtime/wasi/shell"
)
// define the subfolder you want to write cached data into.
// egenv.CacheDirectory just reads some environment variables to determine
// the root of the cache.
func CacheDirectory(dirs ...string) string {
return egenv.CacheDirectory(".eg", "yarn", filepath.Join(dirs...))
}
// here we just setup the various environment variables for yarn
// that enable it to properly cache its packages.
func Env() ([]string, error) {
return envx.Build().FromEnv(os.Environ()...).
Var("COREPACK_ENABLE_DOWNLOAD_PROMPT", "0").
Var("COREPACK_HOME", egenv.CacheDirectory(".eg", "corepack")).
Var("YARN_CACHE_FOLDER", CacheDirectory()).
Var("YARN_ENABLE_GLOBAL_CACHE", envx.VarBool(false)).
Environ()
}
// Here we initialize a runtime using the environment above.
func Runtime() shell.Command {
return shell.Runtime().
EnvironFrom(
errorsx.Must(Env())...,
)
}
Environment Preparation
The other major contributor to the slow iteration cycles is most workloads are reset to zero every time by default. This means any preparation you have to do needs to get repeated every.... single... time... Often we can come up with ways to work around this like having a container repository, caching artifacts (see above), but we have to do it each time.
EG reduces this problem by caching things that make sense to cache automatically. Lets look at an example workload:
package main
import (
"context"
"log"
"eg/compute/console"
"eg/compute/daemon"
"github.com/egdaemon/eg/runtime/wasi/eg"
"github.com/egdaemon/eg/runtime/wasi/egenv"
"github.com/egdaemon/eg/runtime/wasi/eggit"
"github.com/egdaemon/eg/runtime/x/wasi/eggolang"
)
func main() {
log.SetFlags(log.Lshortfile | log.LUTC | log.Ltime)
// Here we setup the workload so it properly will cancel when the TTL expires.
// This isnt strictly necessary, EG will kill a workload that exceeds its TTL + a small grace.
// but its a good idea to do this anyways.
ctx, done := context.WithTimeout(context.Background(), egenv.TTL())
defer done()
mods := eggit.NewModified()
c1 := eg.Container("eg.ubuntu.24.04")
err := eg.Perform(
ctx,
// Here we clone the git repository based on the environment of the workload.
// this only happens once for the entire pipeline. in other systems you'd often
// be cloning the repository for both the backend and the frontend below.
eggit.AutoClone,
// here we build our runner for the operations.
// this container gets stored in the cache and reused
// both for each module suite (backend/frontend)
// and between runs. you dont need to setup a container repository.
// In other systems you often need to build this container for both
// the backend/frontend below unless you manually set up the container
// to be pulled from a repository. but then you're paying the network overhead
// to copy it for both the backend/frontend. In EG we'd only pay the overhead once.
// no matter which route you go.
eg.Build(
c1.BuildFromFile(".eg/Containerfile"),
),
// Here we specify that these operations are independent of each other and can be run concurrently.
// IMPORTANT: currently EG still runs these operations one at a time but we're close to removing that restriction.
// in the mean time the operations get shuffled to ensure that when we do unblock that limitation your
// workloads will work when the transition occurs.
eg.Parallel(
eg.WhenFn(
// Here we check if the daemons directory has any modifications in the changeset.
// unlike github and some other ci/cd platforms it actually checks the entire change
// set between the branches, not just the latest commit.
mods.Changed("daemons"),
// Here we specify the runner to use (our eg.ubuntu.24.04 container) and the operations we
// want to run. You'll note we setup postgresql, run golang's tests, and some linting.
// these run in sequential order.
eg.Module(ctx, c1, daemon.Postgres, eggolang.AutoTest(), daemon.Linting),
),
eg.WhenFn(
// Same deal as above but for our frontend.
mods.Changed("console"),
// Here our module is configured slightly differently.
// We still specify the runner but our execution graph is different.
// first we build our console and then we run multiple operations concurrently.
eg.Module(ctx, c1, console.Build, eg.Parallel(
console.Tests,
console.Linting,
console.CompileCheck,
)),
),
),
)
if err != nil {
log.Fatalln(err)
}
}
Once our workload has run the first time, we dont need to rebuild the containers every execution. In practice we'll still see runs where we have to rebuild, we're using a cache after all. but for the most part your runs will be snappy. In this particular pipeline our runtime time was heavily dominated by building our container and the compilation steps for the frontend/backend.
The automatic caching EG does significantly reduces the compute costs for our system.
Solving the poor developer experience
Most of the problems contributing to a poor developer experience are caused by two decisions most CI/CD ecosystems make. First they tried to obscure the complexity of what we're doing by using a configuration syntax (YAMLScript!) and they treat the problem as an isolated component of the SDLC.
Let's address YAMLScript. Its probably the most common approach next to using bash or another shell environment. But its fundamental flaw stems from the fact that CI/CD workloads are processes not declarations of state. This is why every ci/cd system that uses yaml also has to implement conditional logic and other basic programming primitives (conditionals, explicit dependency graphs, namespaces) that then have to be documented, found and learned. EG avoids this problem by acknowledging that we're defining a process not declaring a state. We get flow control and execution order literally for free.
The kicker? at the end of the day writing a library that converts a YAMLScript system into eg is a pretty trivial, if annoying task.
Builtin IDE support
Since EG is built on top of a widespread and robust language the ecosystem already has the tools you'd want right in your IDE.
- code refactoring
- autocomplete (traditional and LLM based)
- testing libraries.
- dependency management.
having these out of the box makes it much easier to get started, if you already know golang then you don't need to learn a new syntax. There are thousands of resources already in the wild for the language which means EG can focus on documenting just itself and the best part is that documentation will show up right in your IDE.
Large generalized ecosystem of libraries
Again, being able to tap into basically any library that is OS/architecture agnostic makes it a lot easier to build those pipelines. Building an ML model with a giant ETL pipeline? a lot easier when your compute runner has libraries right there for the taking.
We do have some minor limitations here due to using WASI as our base, but they are minor and we're acttively addressing them.
Static analysis tooling
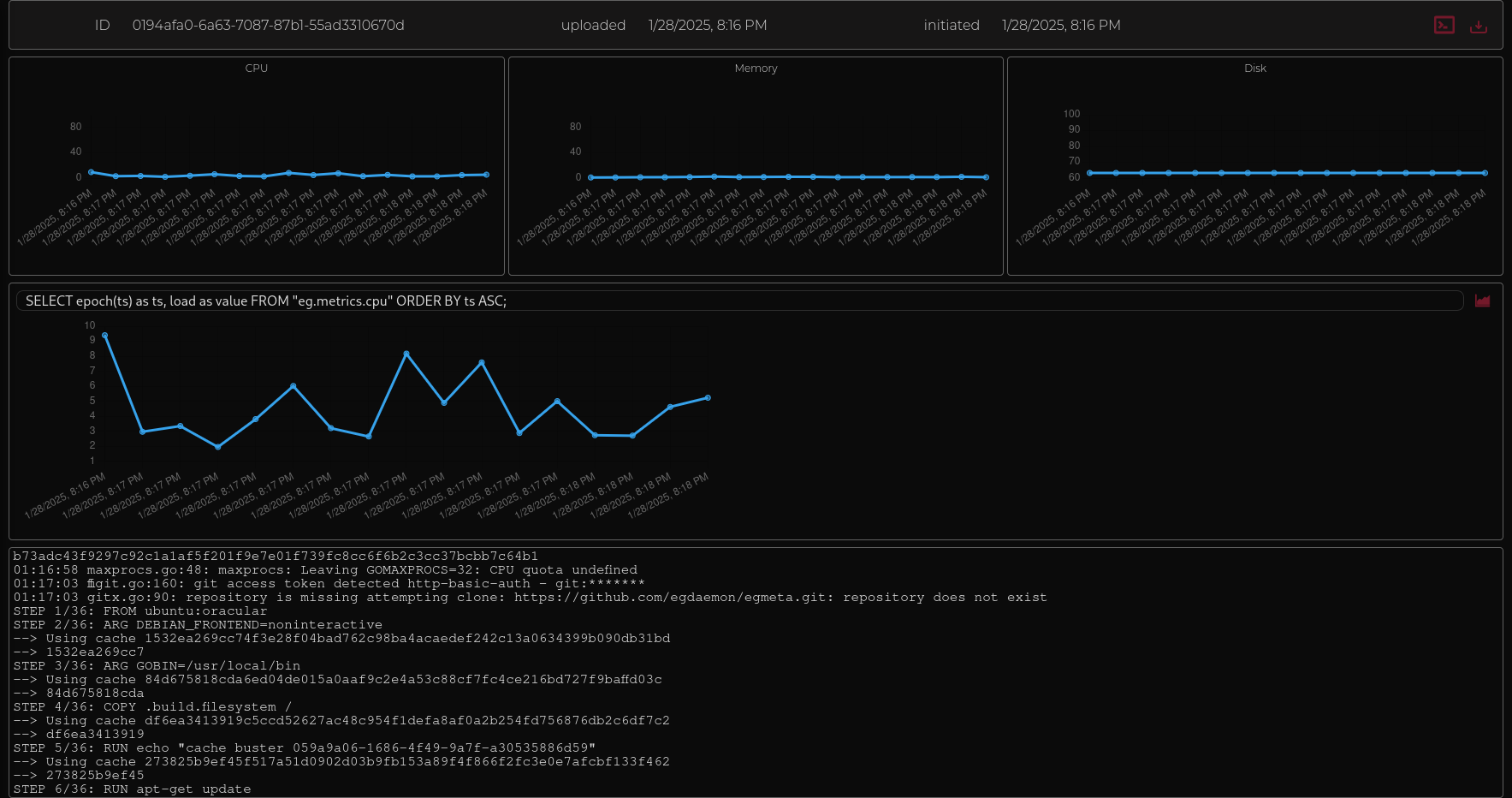
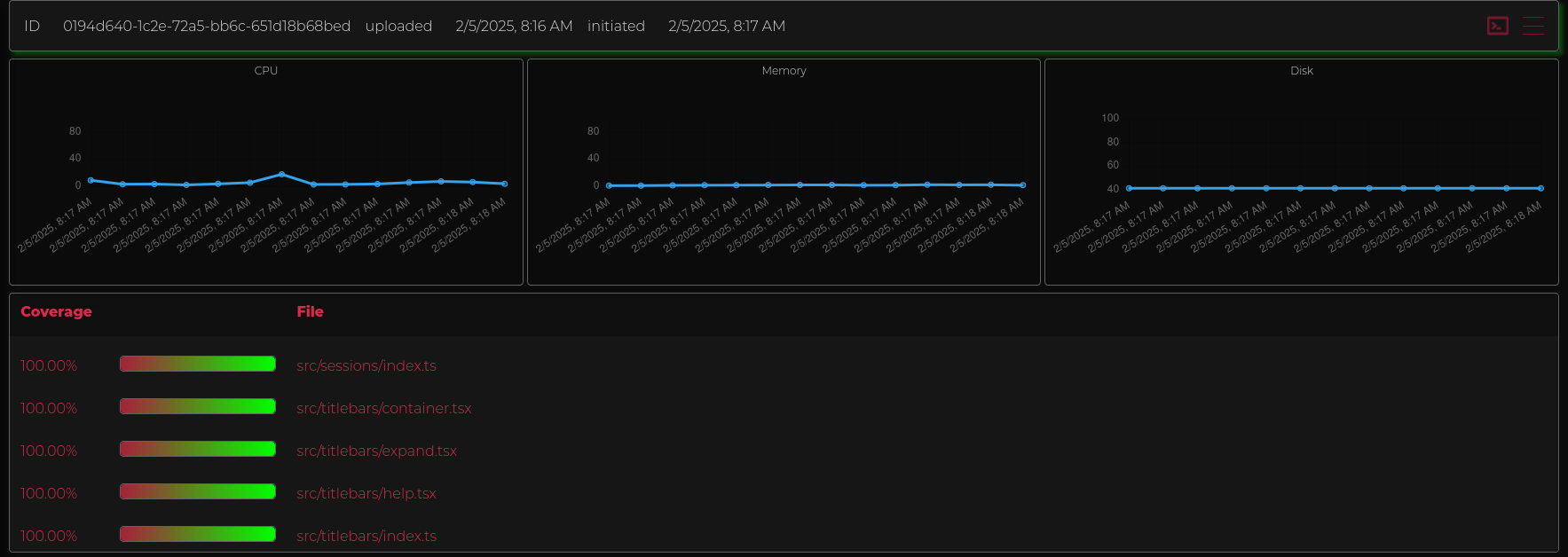
Code analysis is incredibly useful and often you have to go out of your way to set it up. Which is a crying shame. EG has begun integrating common basics like code coverage and profiling into our system, but its not quite ready for prime time yet. but it'll be built off our metrics infrastructure. In the image below the important thing to note is the user provided query we executed and graphed.
basic coverage reports, we plan on more work in this area long term, but anything that generates lcov reports can be processed.
The infrastructure supporting the ability for you to record and then query events from within the workload lets us easily support things like:
- custom events from workloads like ML training metrics.
- code coverage results.
- profiling results.
- runtime metrics like how much time each operation took.
and you can download these metrics and analyse them using your favorite tools, but we're planning on providing the general stuff directly in the workload results dashboard.
Code Reuse
Write a library, use a library cant get much simplier than that. But there is more to it than that. Since EG is built on top of virtualization stacks we can actually reuse code for building our workstation environment directly in our CI/CD pipelines. Lets take a look at an example of a static blog build pipeline sharing operations from the setting up the work station. Essentially EG gives you github codespaces for free at no cost. Let's check it out.
We'll need 3 components:
- our container to declare the environment.
- the operations for installing, compiling, and releasing our site.
- the two processes we wish to define: the ci/cd pipeline and the workstation environment.
Define our container environment file.
# choose our base distribution.
FROM ubuntu:oracular
ARG DEBIAN_FRONTEND=noninteractive
ARG GOBIN=/usr/local/bin
# setup upstream repositories and install some baseline packages.
RUN apt-get update
RUN apt-get -y install software-properties-common build-essential apt-file ca-certificates curl apt-transport-https sudo
RUN add-apt-repository -n ppa:longsleep/golang-backports
RUN add-apt-repository -n ppa:egdaemon/eg
RUN add-apt-repository -n ppa:egdaemon/duckdb
# add the upstream node apt repository.
RUN curl -fsSL https://deb.nodesource.com/gpgkey/nodesource-repo.gpg.key | gpg --dearmor -o /etc/apt/trusted.gpg.d/nodesource.gpg
RUN echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/trusted.gpg.d/nodesource.gpg] https://deb.nodesource.com/node_20.x nodistro main" | tee /etc/apt/sources.list.d/nodesource.list
# install our dependencies
RUN apt-get update
RUN apt-get -y install dput devscripts dh-make dput git uidmap dbus-user-session fuse-overlayfs
RUN apt-get -y install golang-1.23 podman rsync vim eg egbootstrap dpkg tree
RUN apt-get -y install nodejs
RUN systemd-sysusers
RUN systemd-tmpfiles --create
RUN ln -s /usr/lib/go-1.23/bin/go /usr/local/bin/go
RUN go install github.com/princjef/gomarkdoc/cmd/gomarkdoc@latest
RUN /usr/bin/corepack enable && corepack install --global yarn@4.2.2
# run our service manager. its important to note that by using a service manager we can do things like
# build containers that run postgresql, redis, and other databases/services within them without the additional
# complexity of container compose files. just install and enable.
CMD /usr/sbin/init
Next the stages of our pipeline.
package www
import (
"context"
"github.com/egdaemon/eg/runtime/wasi/eg"
"github.com/egdaemon/eg/runtime/wasi/egenv"
"github.com/egdaemon/eg/runtime/wasi/shell"
"github.com/egdaemon/eg/runtime/x/wasi/egyarn"
)
func Build(ctx context.Context, _ eg.Op) error {
console := egyarn.Runtime()
return shell.Run(
ctx,
console.New("yarn config set --home enableTelemetry 0"),
console.New("yes | yarn install"),
)
}
func Tests(ctx context.Context, _ eg.Op) error {
console := egyarn.Runtime()
return shell.Run(
ctx,
console.New("true"),
)
}
func Linting(ctx context.Context, _ eg.Op) error {
console := egyarn.Runtime()
return shell.Run(
ctx,
console.New("yarn eslint -c .eslintrc.prod.js src"),
)
}
func CompileCheck(ctx context.Context, _ eg.Op) error {
console := egyarn.Runtime()
return shell.Run(
ctx,
console.New("yarn tsc --noEmit"),
)
}
func Release(ctx context.Context, _ eg.Op) error {
console := shell.Runtime()
return shell.Run(
ctx,
console.New("cdn upload ...."),
)
}
func Webserver(ctx context.Context, _ eg.Op) error {
console := egyarn.Runtime()
return shell.Run(
ctx,
console.New("yarn dev").Timeout(egenv.TTL()), // run for as long as we can.
)
}
Our CI/CD pipeline:
package main
import (
"context"
"eg/compute/docs"
"eg/compute/www"
"log"
"github.com/egdaemon/eg/runtime/wasi/eg"
"github.com/egdaemon/eg/runtime/wasi/egenv"
"github.com/egdaemon/eg/runtime/wasi/eggit"
)
func main() {
log.SetFlags(log.Lshortfile | log.LUTC | log.Ltime)
ctx, done := context.WithTimeout(context.Background(), egenv.TTL())
defer done()
c1 := eg.Container("eg.www.ubuntu.24.04")
err := eg.Perform(
ctx,
eggit.AutoClone,
eg.Build(
c1.BuildFromFile(".eg/Containerfile"),
),
eg.Module(ctx, c1, www.Build, www.Tests, www.Linting, www.CompileCheck),
eg.Module(ctx, c1, docs.Build),
)
if err != nil {
log.Fatalln(err)
}
}
Our dev environment:
package main
import (
"context"
"eg/compute/www"
"log"
"github.com/egdaemon/eg/runtime/wasi/eg"
"github.com/egdaemon/eg/runtime/wasi/egenv"
"github.com/egdaemon/eg/runtime/wasi/eggit"
)
func main() {
log.SetFlags(log.Lshortfile | log.LUTC | log.Ltime)
ctx, done := context.WithTimeout(context.Background(), egenv.TTL())
defer done()
c1 := eg.Container("eg.www.ubuntu.24.04")
err := eg.Perform(
ctx,
eggit.AutoClone,
eg.Build(
c1.BuildFromFile(".eg/Containerfile"),
),
eg.Module(ctx, c1.OptionLiteral("--publish", "3000:3000"), www.Build, www.Webserver),
)
if err != nil {
log.Fatalln(err)
}
}
Now lets run them:
# Important our development environment functionality is *very much* alpha, hence the required
# experimental environment variable. There is an issue with upstream libraries for containers
# that makes this not work the way we want it to. We'll likely pput some effort in that direction
# soon.
#
# Currently our workstation environments require privileged containers.
# and we tell eg what ports to map from the host into the container.
# 'dev' is just the name we gave the workload, you can basically name it anything.
EG_EXPERIMENTAL_DISABLE_HOST_NETWORK=true eg compute local --privileged --ports 3000 dev
# and here we run the default workload, which in this particular environment is our ci/cd pipeline.
# its the default because its the main function at the root of the .eg directory in the repository.
# the dev workload is the main function of .eg/dev.
eg compute local
Low Server utilization
This one is pretty straight forward, many workload runners in the wild can only run a single workload at a time. Often these workloads dont fully utilize the servers they're running on. EG can not only run individual operations concurrently, but it can actually run multiple workloads concurrently. Greatly increasing your systems utilization.
Securing Shared Runners
Traditionally we've considered shared runners security risks and by and large that is correct given how we as an industry deploy them.
EG's approach is to have each workload is run in its own container and everything is isolated within that container. Naturally there are still risks to this approach. As escaping a container does happen. But our infrastructure does put the effort into isolating them as best we can, and we have plenty of work planned in this area to further reduce the risk when escaping does happen.
The Future
Now that we've covered the bulk of what EG is trying to do, lets talk about where we are going. ATM We're fairly happy with the workload runners and API in general, but we took short cuts for the web application UI. We did this because we don't believe thats where developers should interact with software tooling. Developer tooling should be integrated with the development environment. We intentionally designed EG to be local first for this reason.
Log streaming
This is planned for Q2, we have the bones, we're in the process of testing and putting final touches on it. we want this desperately ourself.
Metrics improvements
we want to allow software to directly interact with the duckdb via a socket within the runtime. We hope to have this done Q1/Q2.
IDE integration
we plan on releasing a vscode plugin for EG. This gives us a ton of benefits:
- coverage reports from your tests runs (that you can reuse in CI/CD) directly integrate with your editor.
- monitor your experiment workloads
- Direct access to the metrics your workloads run locally.
- allows us to mature the local first functionality so alternative UIs/editors can be driven by the community.
macosx support
We're 95% of the way done for macosx just one blocker atm around disk permissions and caching.
architecture emulation
This mostly already done, we just need allow it to be cconfigured correctly. Just havent had a need for it.
Profit sharing with open source developers
given how we've built EG we can track specifically how long each operation takes and where that operation came from. We're hoping by end of Q4 to have a way to automatically profit share with libraries written for EG. But this is currently an apple in our developers eyes. We still need to think about the economics of this. We want to make sure the profit shared is actually meaningful. And thats dependent on a number of factors including usage.
Criminally under utilized systems
Many organizations out in the wild often have criminally under utilized systems even when they have a dedicated operations team. Which is incredibly unfortunate for everyone both in terms of the impact on the environment and on our development environments.
We're drowning in examples of this. We did some consulting work for one company that had a release pipeline that took over an hour to run..... we dropped it down to 5 minutes, with an almost 1 to 1 translation of their github action pipeline into EG. We repeated this with similar outcomes for most of their pipelines.
One example of this came from an FAANG engineering friend. Their workload would burn 30 minutes every run on a task that was easily cachable. Our friend spent months of running that pipeline before they personally became annoyed enough to stop their normal development work and to fix it. It took him a few hours to do this. 30 minutes... every run... for every engineer that had to wait for that process over those intervening months of code changes... The amount of money that alone burned in wasted engineers time had to be staggering. And this is at a FAANG company where they definitely have dedicated operations engineers.
The amount of engineering time wasted at organizations due to misconfigurations in their CI/CD workloads is a little mind numbing, and its not just a cost thing. Think about the implications of the above...
- the context switching engineers need to do as a result of slow workloads
- the amount of energy we as in industry are wasting. Not only do we often save raw dollars for customers in compute and labor costs, but the automatic caching dramatically reduces network usage. which means we're saving compute costs down stream for providers like github, dockerhub, npm, cargo, linux distribution package repositories.
And while fast workloads are great from a cost perspective its not really what EG is about. Our focus at EG is on the development process itself. It just happens to be that when you build to improve the user experience you often improve the overall efficiency of the process.
Try it out
We look forward to those who decide to join us on this journey, we hope you'll bear with us for any initial hiccups over the next few weeks.
If you as a developer just want a reasonably priced tool that makes your life easier when it comes to managing your projects and best in class tooling we want to hear from you!
If your organization is struggling with slow/expensive workloads or high support costs for your developer teams, reach out we'd love to help. Finally check out our promotional offers below.